Embedded Linux Development Course - Kernel (pt. 7)
Arquitetura Geral
A figura a seguir, apresenta uma visão geral do kernel Linux. Basicamente, é ele quem gerencia todo o hardware do sistema e as comunicações entre as partes, uma vez que o usuário não possui acesso direto à nenhum componente.
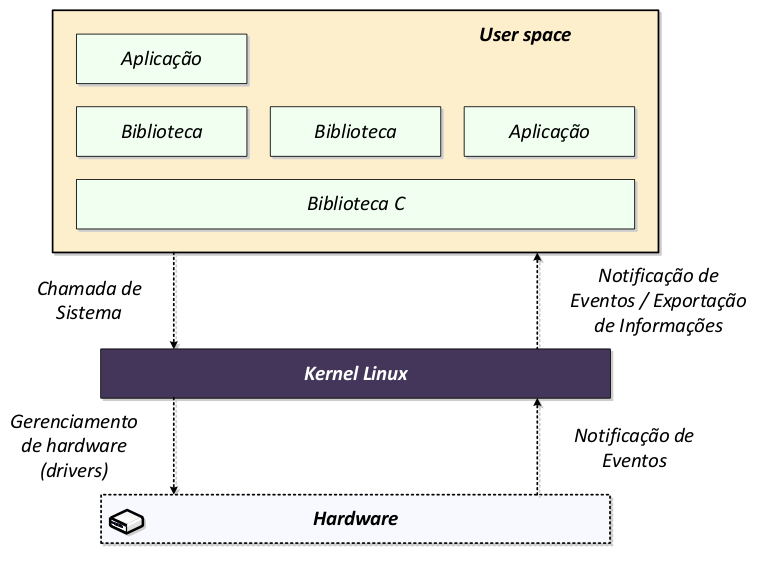
Além disso, ele gerencia recursos como CPU, Memória, I/O, HD, qualquer dispositivo de hardware conectado ou built-in do sistemas. Ele gerencia isso através de um conjunto de APIs bem portáteis, que são independentes da arquitetura e do hardware, lembra-se que no início do treinamento foi comentado que uma das grandes contribuições do Ritchie foi portar o UNIX pra linguagem C e deixá-lo modular, e este princípio é mantido até os dias de hoje e isto torma tudo mais simples e abstraído.
Outras responsabilidades do kernel, é por exemplo, fazer o tratamento de acesso concorrente de hardware de diferentes aplicações. Normalmente um dispotivo como uma porta serial, interface de rede é utilizada por mais de uma aplicação, é responsabilidade do kernel fazer essa “multiplexação” de componentes.
Usualmente tem-se uma chamada de sistema da aplicação, então o kernel atende-a ou insere a mesma na fila de execução, gerencia o hardware, como leitura da porta serial por exemplo. Então, o hardware notifica o kernel que o dado pode ser lido e o kernel exporta o dado para aplicação. Ou uma interrupção também de hardware, quando algum evento ocorre, o hardware gera uma notificação para o kernel e o mesmo realiza o tratamento.
Gerenciamento de Processos
Primeiramente devemos definir o que são processos do ponto de vista do kernel Linux. Podemos então, definir um processo, como um programa (normalmente um arquivo objeto ou binário armazenado em uma mídia, como o seu cartão micro SD) que se encontra no meio de sua execução, ou seja, é um programa em execução, ponto.
Um processo, possui um Process ID único para identifica-lo perante o kernel. Este PID nada mais é do que um contador, e está associado a um conjunto de recursos do sistema operaciona. Tais como, arquivos abertos, mapeamento de memória, isto é, a região da memória reservada para a execução daquele programa e etc.
Para observar os processos que estão executando no Linux, e também seus PIDs e outras características, podemos utilizar o comando
ps -A, ou ainda através da aplicaçãohtop.
Cada processo contém, pelo menos, uma ou mais linhas de execução, que também são chamados de threads.
Threads vs. processos
Threads são treichos de código que podem ser independentemente manipulados pelo escalonador. Isto significa que podem ocorrer de forma, paralela e sequêncial. Tipicamente, as threads são partes de constituintes de processos do sistema operacional.
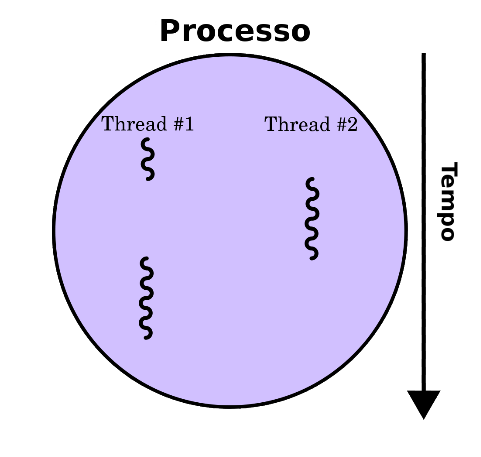
A implementação de threads e processos é diferente em alguns sentidos, mas de forma geral as threads são componentes dos processos. Podem existir diversas threads de um processo e estas estarem executando de forma concorrente e compartilhando recursos como por exemplo regiões de memória. Enquanto processos distintos não compartilham desses recursos. Em particular, as threads de um processo compartilham os endereços de memória e outros recursos.
De forma resumida podemos listas as diferenças das threads e dos processos:
Processos:
- São tipicamente independentes;
- Tem muito mais estados e informações que uma thread;
- Possuem espaços endereçados;
- Interagem apenas através de IPC.
Thread:
- É um sub-código de um processo;
- Multiplas threads pode fazer parte de um processo;
- Threads de um processo compartilham de seu estado, memória e etc;
- Threads compartilham seus endereços de memória.
Estrutura de gerenciamento
O kernel Linux gerencia o conjunto de processos através de uma estruturade de dados, mais precisamente, uma lista circular duplamente encadeada. Onde cada nó representa um processo, contendo informação como memória mapeada, proccess ID, parent process ID, isto é, o process ID de quem iniciou aquele processo. Enfim, cada nó é uma estrutura de dados que contém toda a informação relevante de um processo específico.
Cada thread possui um contador de programa, que tem a mesma função do process ID, mas ele serve para identificar a thread, uma região de stack e uma cópia dos registradores da CPU.
O kernel não faz diferenciação entre processos e threads, do ponto de vista de escalonamento e afins. Isto quer dizer que quando um processo novo é criado no Linux, basicamente é criado um clone do processo que o criou (fork), e algumas informações são modificadas pelo kernel.
Escalonador
Para entender o funcionamento da gerência de processos no Linux, ou ainda um sistema multi-tasking, é necessário primeiramente, entender que ele é um sistema preemptivo, ou seja, ele permite troca de contexto. Ele é capaz de parar um processo no meio de sua execução (se necessário), e atribuir um outro para a CPU. Esta é a base para o funcionamento do sistema, o conceito de sistema preemptivo.
O escalonador padrão do Linux, é chamado de CFS (Completely Fair Scheduler). Esse escalonador tenta modelar uma CPU multi-tasking ideal, essa ideia de CPU multi-tasking ideal, é definida como um processador que rodaria todos os processos em paralelo, dando uma porcentagem igual de tempo de CPI para cada um, ou seja, por exemplo: se tivessemos 4 processos nessa CPU, eles seriam executados em paralelo, cada um usando 25% da CPU. Nessa CPU, nenhuma tarefa receberia mais CPU que outra.
O CFS tenta modelar esse CPU hipotético, mantendo um registro de “injustiça” de cada processo em relação aos outros. Pois na prática, pensando em CPU single core, somente um único processo é executado por vez, enquanto na CPU ideial, não existe injustiça. Uma vez que, ela seria capaz de executar todo mundo ao mesmo tempo, paralelamente, dividindo o processamento igual pra cada uma.
Quando uma task é executada, faz com que o tempo que o CPU “deve” para as outras tasks seja aumentado. Além disso, o kernel oferece também, um framework de classes de escalonamento, onde cada classe permite a utilização de um escalonador diferente, como FIFO ou RR (Round Robin). Em geral quando se inicia uma thread, é fornecida a opção de selecionar o tipo de escalonador que se prefere.
Dentre as funcionalidades do kernel, existe também um escalonador, que é inclusive o responsável por gerenciar threads da classe FIFO e RR, para aplicações de real-time ou seja, ele tem prioridade sobre o CFS, buscando atingir os critérios de tempo real das operações.
No entando, o Linux não pode ser considerado um RTOS, não em sua forma padrão, pois ele não é completamente determinístico, ou seja, existem alguns trechos do kernel onde a latência pode ser bem alta, em relação a latências normais e mais que isso, há trechos com latências variáveis.
Os critérios de tempo real, não envolvem velocidade de processamento e sim o cumprimento de restrições temporais e deadlines. Latência é o tempo que o kernel leva desde uma solicitação / interrupção para executar um processo e a execução efetiva desse processo.
Existe um conjunto de patches, conhecidos como PREEMPT_RT que são aplicados no kernel e até melhoram esse cenário_,_ claro que depende do hardware mas em geral oferece uma latência de centenas de microssegundos.
Uma opção, para utilizar o Linux para aplicações real-time é a utilização de um segundo kernel em conjunto com o Linux, como RTLinux, RTAI, Xenomai. Desta forma, sua máquina fica na verdade com dois kernels sendo executado, e o Linux funciona como um alimentador para o kernel de tempo real. Ou seja, ele apenas comanda o kernel, é como se o kernel Linux fosse um processo do kernel de tempo real, em geral esses kernels de tempo real costumam baixar a latência para unidades de microssegundos, novamente, depende do hardware.
Gerenciamento de Memória
O kernel Linux, assim como a maioria dos sistemas operacionais modernos, implementa o mecânismo de memória virtual para gerenciar a memória física. O acesso à memória é realizado através de endereços virtuais, que são convertidos via hardware para endereços físicos da memória. O hardware que faz esse gerenciamento e conversão de memória virtual para física, é a MMU (Unidade de Gerenciamento de Memória) e conforme comentado durante o treinamento, normlamente ela é um recurso do processador.
Em geral, a MMU fornece e gerencia uma tabela de páginas para o sistema operacional e quando algum processo ou aplicação deseja acessar um endereço físico, o kernel consulta essa tabela e extrai o endereço necessário.
Via de regra, sistemas com MMU fornecem várias funcionalidades, tais como:
- Um maior endereçamento de memória para os processos;
- A famosa região de SWAP, apesar de ultimamente estar ficando menos utilizada. Pois os tamanhos de RAMs estão aumentando muito. Normalmente a SWAP é uma simulação de memória física, no disco rígido, é claro que fica um pouco mais lento (dependente do processo de leitura/escrita do driver) que a memória RAM normal. Mas é mais rápido do que uma troca de contexto entre memória e disco rígido. A SWAP é paginada também, então do ponto de vista do sistema ela é tratada literamente como uma memória secundária é possível recuperar e salvar páginas da SWAP.
- Oferece uma certa proteção, onde cada processo só enxerga seu espaço de endereçamento, normalmente, quando se escreve um programa em C e tenta-se utilizar instruções pouco elegantes como
go-to, o programa tenta acessar de alguma forma uma aŕea fora de seu endereçamento e ocasiona um erro de S_egmentation Fault,_ ou seja, não é possível acessar endereços fora de seu escopo de memória. - Apesar de ter essa proteção, ela também oferece uma flexibilidade para os programadores. Esta é a possibilidade de compartilhar a memória entre dois ou mais processos. Existem alguns mecânismos para esse tipo de manipulação, chamados de mecânismos de comunicação inter-processos (IPC) e com sorte, iremos usar alguns deles na prática, ao final do treinamento. Como Queue Messages, Semáforos, Socket, Signals e etc.
- Arquiteturas com MMU também suportam Memory Mapping, isso da possibilidade de mapear uma regiao da memória, uma ou mais páginas por exemplo entre processos. É uma função útil, assim que um processo termina de escrever em uma região e outro processo pode ter acesso á ela, é uma área visível para mais de um processo.
Sistema de Arquivos Virtuais
Uma das funcionalidades mais atrativas do kernel Linux é seu sistema de arquivos virtuais. Através deste, o kernel disponibiliza informações do próprio kernel e sistema através de arquivos virtuais.
Arquivos virtuais permitem que aplicações “enxerguem” diretórios e arquivos que não existem fisicamente, tanto as aplicações quanto o usuário conseguem enxergar diretórios e arquivos que na verdade não existem fisicamente num disco rígido por exemplo. Esse tipo de arquivo é criado e atualizado on the fly, ou seja, assim que uma requisição é feita. Apesar do usuário e aplicação poderem enxergá-los o tempo todo no sistema.
Quem implementa essa funcionalidade é uma camada chamada de VFS (Virtual FileSystem). Ela possibilita que funções de acesso como read, write, open e close, por exemplo, sejam utilizadas em arquivos virtuais. Para melhor exemplificar essa funcionalidade segue os seguintes exemplos.
- Exemplo 1: Copiando um arquivo físico em um dispositivo de armazenamento (pendrive).
Para copiar um arquivo no Linux, utilizamos o comando cp seguido do arquivo/diretório a ser copiado e o endereço para onde desejamos copia-lo.
cp /dsle2020/teste.txt /mnt/pendrive
Nota que o arquivo teste.txt que esta fisicamente presente dentro do RootFS ou dentro do cartão SD será copiado de /dsle2020/ para /mnt/pendrive/ mesmo esse diretório pendrive/ sendo o pendrive propriamente dito, físico.
O kernel simplesmente copia o arquivo para o pendrive (físico), note que o conteúdo da pasta pendrive não existe no seu sistema apesar de enxerga-la. Mas a ideia é, sua árvore de diretótios tem a pasta /mnt na raíz, então monta-se seu pendrive nessa pasta e quando rodar o comando para listar os arquivos, ls, nessa pasta. Você verá e conseguirá acessar todo o conteúdo do pendrive, mas na verdade não existe nada no seu disco rigido, não existe uma cópia do pendrive no disco, está tudo no pendrive e quando você faz a copia do arquivo o mesmo acontece ele vai direto para o pendrive.
- Exemplo 2: Listando informações de memória em uso pelo sistema.
Para listar informações de um arquivo, por exemplo, podemos executar o comando cat. Não obstante, existe um diretório específico do Linux, chamado /proc/ que quando desmontado, não possui nenhum arquivo (caso abra o cartão SD no seu computador, por exemplo). Este diretório contém um diretório para cada processo em execução, mais especificamente um diretório virtual.
Além disso, é possível listar o arquivo meminfo, que exibe informações de memório em uso, mas novamente, fisicamente no cartão SD, não tem nada.
cat /proc/meminfo
- Exemplo 3: Escrevendo na porta serial.
O último exemplo, é escrever uma string ou caracteres na porta serial. O diretorio /dev/ contém arquivos para todos os dispositivos ativos / ou conectados ao sistema. Situação similar a anterior, caso você conecte ao seu computador e inspecione a pasta ela estará vazia.
O Linux popula esse diretório em tempo de execução, mas enfim, um dos arquivos que existe dentro desse diretório representa sua porta serial. Quando você escreve algum arquivo nele, o kernel faz o direcionamento ao hardware físico pra você, simples assim, se tem driver funcional você verá um dispositivo no seu computador.
echo “teste” > /dev/ttyS0
Kernel Space vs. User Space
Como mencionado anteriormente no treinamento, o Linux trabalha com o conceito de KS - kernel space e US - user space, essa é uma divisão bem definida. Tal divisão não é feita na memória física, o kernel faz através daquela tabela de páginas de memória que a MMU cria o kernel divide algumas páginas para rodar aplicações do usuário e outras para o kernel.
Como mencionado anteriormente no treinamento, o Linux trabalha com o conceito de KS - kernel space e US - user space, essa é uma divisão bem definida. Tal divisão não é feita na memória física, o kernel faz através daquela tabela de páginas de memória que a MMU cria o kernel divide algumas páginas para rodar aplicações do usuário e outras para o kernel.
O kernel, que roda no kernel space, roda em modo priviligiado, isto significa que ele tem acesso total aos recursos do sistema, desde de acesso a arquivos quanto à hardware, por exemplo.
O kernel, que roda no kernel space, roda em modo priviligiado, isto significa que ele tem acesso total aos recursos do sistema, desde de acesso a arquivos quanto à hardware, por exemplo.
Ao passo que as aplicações, que rodam em user space, não tem permissão para acessar tais hardwares diretamente, ou seja, elas rodam em modo restrito.
Ao passo que as aplicações, que rodam em user space, não tem permissão para acessar tais hardwares diretamente, ou seja, elas rodam em modo restrito.
System calls
Portanto, há a necessidade da uma interface de comunicação entre suas aplaicações e o kernel, estas que são as denominadas chamadas de sistemas ou system calls. Tais como as funções apresentadas em momentos anteriores do treinamento, por exemplo: read, write, open, estas são todas chamadas de sistema.
Atualmente o Linux possui aproximadamente 400 chamadas de sistema, dos mais variados tipo, pode até ser que esse número já tenha aumentado no momento deste treinamento. São as chamadas de sistema que fornece suporte para operação de arquivos, criação e gerenciamento de processos e threads, comunicação entre processos, timers, operações de rede e etc.
As rotinas já apresentadas read, write, open e pthread_create, por exemplo, são na realidade abstrações das system calls, elas são desenvolvidas em linguagem C e pertecem a biblioteca C padrão.
Desta forma, quando executa-se um, por exemplo, man em um terminal, é apresentado os parâmetros da função, bem como um detalhamento sobre a rotina. Todo esse suporte foi criado pelos desenvolvedores da biblioteca C que o implementaram essa abstração de forma a facilitar a utilização do lado do usuário e deixar os parâmetros, principalmente, no formato desejado pelas chamadas.
Além disso, essa interface costuma ser bem estável, a cada nova versão/release do kernel, os desenvolvedores só podem adicionar novas chamadas e não remove-las (lembram da filosofia de desenvolvimento da mainline?), garantindo assim que as chamadas continuem robustas e sem a necessidade de refatoração por parte do usuário.
Versionamento
Antes da versão 2.6, existiam basicamente 2 árvores de desenvolvimento do kernel Linux. Uma de versões estáveis, identificadas por um número par no centro. E outra de versões de desenvolvimento que possuiam números ímpares no centro, identificando-as.
As versões estáveis costumavam ser lançadas a cada 2-3 anos, ao passo que as versões de desenvolvimento não tinha um padrão fixo normalmente existiam várias de desenvolvimento entre cada estável, por exemplo 2.1.1.
A partir de 2003, os desenvolvedores começaram optaram por manter apenas uma arvore de desenvolvimento, e unificaram ambas em uma única árvore considerada estável, onde uma nova versão era lançada a cada três meses.
Em seguida, em 2011, devido ao número da versão começar a ficar alto demais foi mudado para um novo padrão, que foi o kernel 3.0 (reza a lenda que um dos mantenedores do kernel subornou o Linus com uma garrafa de whisky). Em seguida, em 2015 mudou novamente de 3.19 para 4.0 e hoje estamos na versão estável do kernel 5.0.
Ainda existe o terceiro número que indica releases intermediários de desenvolvimento, por exemplo: o 5.0, 5.1 e etc passou a ser considerado versões estáveis a cada 3 meses.
Além dos releases estáveis, algumas empresas, comunidades e mesmo distribuições, não gostaram muito deste padrão da árvore devido a frequência de lançamento, que muitas vezes devia ser atualizada para os desenvolvedores.
Fontes
Os fontes das versões oficiais do kernel Linux, anda são as liberadas por Linus Torvalds. É possível baixá-las diretamente na página oficial do projeto, eles tem um diretório público com todas os releases, ou ainda através do repositório git do próprio Linus.
Muitos fabricantes costuma fornecer suas próprias versões do kernel Linux, por exemplo a Freescale, HardKernel, entre outras.
Normalmente essas versões são focadas no suporte do hardware desses fabricante, via de regra são defasados em relação ao mainline, pois é difícil acompanhar a frequência de um release a cada três meses.
Além destas, as comunidades de desenvolvimento também fornecem suas próprias versões, as vezes voltadas a uma arquitetura específica. Por exemplo, existe o projeto ArchLinux ARM que fornece releases para diversas placas que usa ARM, muitas outras distribuições fazem isso, como Ubuntu e Debian.
Algumas outras podem ser específicas para drivers, geralmetne comunicação de rede, por exemplo uma das buzzwords da moda, o IoT. Inclusive a Microsoft lançou seu proprio branch do Linux para IoT, na plataforma Azure.
Existem as comunidades focadas em real-time como Xenomai, RTAI e etc. Normalmente são bem atrasadas em comparação com o mainline, principalmente devido ao uso específico.
ls linux/
| arch | block | certs | COPYING CREDITS |
| crypto | Documentation | drivers | firmware |
| fs | include | init | ipc |
| Makefile | Kbuild | mm | Kconfig |
| net | kernel | README | lib |
| REPORTING-BUGS | MAINTAINERS | samples | scripts |
| security | sound | tools | usr |
| virt |
Essa é a estrutura geral do diretório de fontes do kernel Linux.
- O diretório
archcontém basicamente todo código das arquiteturas suportadas, é possível inspecionar através de umlsno diretório e visualizar as arquiteturas; Documentationoferece alguma documentação do kernel, mas normalmente é desatualizada;driversé o maior diretório do kernel, aproximadamente 60% do tamanho total e contém os drivers do kernel Linux;- O diretório
firmwarecontém alguns firmwares para hardwares, alguns são necessários para rodar alguns drivers; - O diretório
fscontém os arquivos de implementação da camada de arquivos virtuais; includecontém os headers;initarquivos relacionados a boot e inicialização;makefilemontado para compilação e configuração;kernelsão os core subsystems, como o escalonador de processos e etc;ipccodigo relacionado à comunicação IPC;libcontém bibliotecas auxiliares;mmgerenciamento de memória.
Esses são os principais diretório do kernel Linux.
Licença
O Linux é liberado sob licença GPLv2 e na prática isso significa que: caso você receber ou comprar um hardware com Linux embarcado, você tem direito aos fontes, inclusive direito de editá-los e redistribuí-los. No entanto, se o fizer, você deve liberar sob as mesmas condições.
Em relação aos drivers o a discussão é muito mais longa, tem brigas até hoje nas comunidades, pois tem muitas empresas que até hoje não liberaram os fontes, apenas binários. Um caso clássico é a NVidia e a cena do Linus mostrando o dedo do meio durante o congresso. Dizendo que era a pior empresa que a comunidade já havia lidado e que o fato de terem muitos bugs era justamente por não terem liberado todos os fontes dos drivers e etc.
Via de regra, a opinião da comunidade é de que drivers fechados são ruins. Em termos legais, as empresas distribuem “módulos” para o kernel.
Além das discussões, os efeitos práticos da licença do kernel Linux tem influências práticas. Por exemplo, para desenvolver um conjunto de drivers ou módulos, não há a necessidade de começa-los do zero. Como os drivers são disponibilizados sob licença GPL é possível reaproveitar-se de outros drivers e implementar a sua solução.
Após realizada a implementação, é possível integra-lo à árvore do kernel Linux e assim disponibilizado para a comunidade. Isso em termos práticos te garante algumas coisas, como: um conjunto de desenvolvedores realizando a manutenção do seu drivers, novas implementações e aprimoramentos através dos membros da comunidade que podem levar até mesmo a APIs internas do kernel. Suporte da comunidade implica em mais desenvolvedores analisando seu código e um efeito secundário disso é a visão positiva da empresa perante as comunidades, sem falar no currículo do desenvolvedor.
Configurando o Kernel
Como apresentado durante o treinamento, em outras seções, o kernel Linux possui uma infinidade de de drivers, protocolos de rede e itens de configuração. Desta forma, como imagina-se existem milhares de opções disponibilizadas para a configuração, permitindo incluir ou não cada um dos items disponibilizados, ou seja, incluir ou não cada uma das partes do kernel Linux.
Esse processo de configuração é realizado para que o kernel Linux, consiga ser compilado com as partes requeridas para uma determinada arquitetura. Para facilitar o processo, foram definidos conjuntos ou grupos de configuração.
Desta forma, o conjunto de opções é montado com base em:
- Tipo do hardware (drivers);
- Funcionalidades desejadas (sistema de arquivos suportados, protocolos e etc).
Arquitetura
Por padrão, a configuração do kernel Linux é compilada para a arquitetura nativa, ou seja, o kernel irá compilar para a mesma arquitetura que o sistema host. Porém, isso pode ser facilmente ajustado através da mudança da variável de ambiente ARCH. Alterando-a é possível alterar a arquitetura de compilação do kernel Linux. Portanto,
export ARCH=arm
Atribuindo arm para a variável ARCH, estamos modificando para qual arquitetura o kernel deverá ser compilado. Em especial, neste caso, para a arquitetura arm. Não se esqueça, que para ver as arquiteturas disponíveis no kernel Linux, basta analisar as disponíveis no diretório padrão.
Desta forma, o kernel Linux é compilado então, utilizando-se os headers e fontes, para a arquitetura ARCH.
Build System
O processo de build do kernel Linux é baseado em vários arquivos Makefile. Este processo é automatizado, cada arquivo é responsável por agrupar, organizar e compilar cada parte do kernel. Contudo, nossa interação é somente com o Makefile principal, este esta presente na raiz dos fontes.
Por exemplo,
cd linux-rpi-4.14.y
make <target>
A interação irá ocorrer entre todos os Makefiles internos, definindo configuração, compilação e instalação.
Arquivos de Configurações Prévias
Assim como outras ferramentas, é difícil definir uma configuração que irá funcionar com seu hardware e RootFS. Como principal recomendação, é instruído a não começar do zero esse processo. O ideal é começar por algo já testado, previamente configurado.
Para tal, existem arquivos de configuração prévia relacionados a cada uma das arquitetura disponíveis, isto é, a cada família de processados que é suportada pelo kernel. Este arquivos estão disponíveis em arch/<arch>/configs/.
Além disso, é necessário carregar estes arquivos de configuração esta etapa é simples, basta realizar a execução do comando make sob o processador que deseja.
make cpu_defconfig
Por exemplo, no caso do nosso treinamento, estamos interessados em carregar as configurações disponíveis para a RPi 3. Assim, o arquivo se encontra em arch/arm/configs/bcm2709_defconfig, então parar carregá-lo, basta executar:
make bcm2709_defconfig
Criando Arquivos de Configuração
Caso deseja-se não utilizar um arquivo de configuração já definido, como o apresentado na seção anterior. É possível realizar a criação de um novo arquivo de configuração, este pode até mesmo, ser baseado em um arquivo já existente, como também pode ser desenvolvido do zero.
Para criar o seu próprio arquivo de configuração, basta simplesmente executar o comando:
make savedefconfig
Isto irá gerar um arquivo simples com a configuração mínima requerida. Então, é possível editá-lo então, de acordo com seus gostos e os requisitos da sua plataforma. Em seguida, é possível então, incluí-lo na na àrvore do kernel Linux e compartilhá-lo na comunidade:
cp yourdefconfig arch/<arch>/configs/yourdefconfig
Claro que não é simplesmente fazer o commit do módulo e ele entrará na árvore, ele deve ser testado, aprovado e etc.
Arquivos de Configuração
Todas as configurações que são/foram realizadas, são salvas em um arquivo .config no diretório raiz dos fontes.
Este arquivo, nada mais é do que um arquivo texto normal. Sua estrutura é bem simples, consiste em um conjunto de dados do tipo chave=valor, e é criado pelo próprio Makefile:
CONFIG_ARM=y
...
O processo de configuração é um proesso delicado, ainda mais crítico devido as dependência. Isto é, as opções selecionadas devem carregar suas próprias dependências e isto é um tanto quanto difícil de ser fazer manualmente. Para tal, existem formas para facilitar a configuração, através de interfaces de textou ou gráficas:
make menuconfig-> interface de texto;make nconfig-> interface de texto;make gconfig-> interface gráfica;make xconfig-> interface gráfica.
Todas essas interfaces editam o mesmo arquivo, .config, desta forma tanto o resultado de ambos os processos tende a ser idêntico, como viabiliza trocar de uma interface para outra ao longo do processo. Pois editam o mesmo arquivo e exibem o mesmo conjunto de opções.
Arquivo Final
Após realizar a configuração, o arquivo final gerado é um binário único. Portanto, a imagem do kernel Linux que foi construída é resultado de um processo de compilação, linkagem de arquivos-objetos correspondentes às funcionalidades habilitadas é um binário único.
Este arquivo vai ser carregado pelo bootloader no processo final de seu ciclo, no caso da RPi do treinamento, será carregado após a inserção do U-Boot no processo. E esse kernel é carregado para dentro da memória RAM, ao passo que o bootloader é desmontado. Em seguida, quando o kernel é inicializado, ou seja, quando o mesmo começa a sua execução, todas as ferramentas e funcionalidade tornam-se disponíveis.
Mas como o esperado, é possível realizar compilar essas funcionalidades de maneira dinâmica e de maneira estática. Em outras palavras, é um código compilado como qualquer outro, sua linkagem pode ser dinâmica ou estática.
Através da linkagem dinâmica suas funcionalidades são tratadas como módulos, são normalmente referenciadas como modules. Os módulos são armazenados no RootFS como arquivos e são carregados dinamicamente, em tempo de execução.
Ao passo que da maneira estática, as funcionalidades são linkadas de forma estática à imagem do kernel.
Opções de Configuração
Algumas das opções fornecidas esperam entradas booleanas, ou são habilitadas ou não são habilitadas. Desta forma, tomando como exemplo o processo através do make menuconfig, temos:
- [*] Funcionalidade 1 (habilitada)
- [ ] Funcionalidade 2 (desabilitada)
Basicamente, a funcionalidade que carrega a marcação [*] é incluida no kernel ou caso seja colchetes vázios (no menuconfig) a funcionalidade é removida do kernel.
Além disso, existe opções que esperam operações de três estados.
- < > Funcionalidade 1 (desabilitada)
- < * > Funcionalidade 2 (habilitada como built-in)
- <M> Funcionalidade 3 (habilitada como módulo)
Um estado que remove a funcionalidade do kernel, um estado que incluí de forma built-in a funcionalidade no kernel e uma última que inclui no kernel como módulo.
Por fim, algumas opções necessitam que seja especificado algum comportamento, como tamanho de buffer, número de bytes, caminho relativo de algo e etc. Assim, são esperados tipos diferentes de entrada, como inteiros, strings e hexadecimais.
Opções com Dependência
Como mencionado anteriormente existe algumas opções do kernel Linux que possuem dependências de outros módulos. Por exemplo:
O driver de um dispositivo I2C que é disponibilizado requer que o suporte ao barramento I2C seja habilitado no kernel. Desta forma, ao carregar a funcionalidade I2C é necessári o que sua dependência, barramento habilitado, seja satisfeita. Essa tarefa é feita automaticamente caso esteja utilizando as ferramentas automatizadas, porém ser for de forma manual, você deve garantir o mesmo.
Outro exemplo é o framework de porta serial (serial core) é habilitado automaticamente quando um driver de UART é habilitado.
Validação de Configuração
Suponha que o arquivo .config foi alterado manualmente ou mesmo que você deseja utilizar a configuração em outra versão do kernel Linux. É necessário fazer uma validação para garantir a consistência das configurações escolhidas.
make oldconfig
Para tal, é fornecido uma ferramenta que caso haja alterações a serem feitas, como por exemplo, selecionar um parâmetro específico que não existia na versão anterior do kernel é solicitado que você insira esses parâmetros, por exemplo. Este processo é totalmente diferente do menuconfig onde é inserido valores padrões para parâmetros não definidos ou novos.
Portanto, este deve ser chamado sempre que o arquivo .config for alterado manualmente ou os fontes do kernel forem atualizados e deseja-se utilizar a mesma configuração.
Compilando o Kernel
Definindo o Compilador
O compilador que é chamado pelo Makefile do kernel é definido no arquivo como:
$(CROSS_COMPILE)gcc
Desta forma, para se não definirmos esta variável, deixando-a vazia, iremos compilar nativamente o kernel Linux. Observe que se $CROSS_COMPILE for vázio apenas gcc será chamado. Contudo, desejamos compilar o kernel para uma plataforma target, utilizando cross-compilação. Para tal, basta atribuir a variável $CROSS_COMPILE com o alias do toolchain desejado, portanto:
make ARCH=arm CROSS_COMPILE=arm-linux-
Lembre-se de deixar o “ - “ no final, pois ele será concatenado com “gcc”. Assim, teremos por exemplo:
arm-linux-gcc, que é de fato nosso cross-compilador. Além disso, é importante pensar que este é apenas o prefixo da ferramenta, que pode ser concatenado as outras ferramentas como gcc, ar, ld, strip e etc.
Além disso, neste momento é possível se utilizar de ferramentais normais de compilação do gcc. Assim, é possível por exemplo, para acelerar o processo, utilizar a flag de threads na compilação. Para tal, basta executar o comando make seguido de -ji, onde i representa o número de threads que podem rodar em paralelo.
Saída
Ao final do processo make, são geradas algumas imagem. Uma delas é a vmlinux, ela esta gerada no diretório raiz, no formato ELF, descomprimida mas não é utilizada para execução, pois não é inicializável, sendo utilizada mais para depuração.
Além desta, em arch/<arch>/boot/, são geradas outras imagem, sendo Image uma imagem genérica do kernel Linux, que ao contrário da vmlinux é inicializável e comprimida. Bem como, as imagem bzImage (x86) e zImage (ARM), que são as imagens inicializáveis do kernel, de acordo com a arquitetura, sendo a de nosso interesse a da arquitetura target (ARM). Por fim, há uma última imagem que é a uImage esta é opcional, sendo uma imagem do kernel para o U-Boot.
Instalando o Kernel
Para fazer a instalação do kernel Linux que compilamos é simples, basta chamar o comando install do próprio Makefile:
make install
Este, faz a instalação no host por padrão, ou seja, na máquina de desenvolvimento.
Os arquivos gerados estão disponíveis no diretório /boot. São gerados alguns arquivos, como:
- vmlinuz-<version>: Imagem do kernel comprimida;
- System.map-<version>: Endereços dos símbolos do kernel (obsoleto);
- config-<version>: Arquivo de configuração desta versão do kernel;
Além disso, é possível alterar o diretório raiz de instalação do arquivos, este é feito através da variável de $INSTALL_DIR:
make INSTALL_DIR=<install_dir> install
Normalmente esse procedimento não é utilizado em sistemas embarcados. Via de regra, copia-se a imagem do kernel Linux para algum dispositivo de armazenamento, como um cartão SD.
Device Tree
De forma geral, o devicetree é uma estrutura de dados que descreve os componentes de hardware de uma plataforma ou computador. Assim, o sistema operacional, mais precisamente o kernel, pode manipular esses componentes, por exemplo, processador, memória, barramento e outros periféricos.
Um device tree é uma forma flexivel de definir componentes de hardware de um sistema. Usualmente, o device tree é carregado por um bootloader e passado então para o kernel. Além disto, é possível agrupar o device tree com a imagem do kernel. Embora seja possível agrupar o device tree com a própria imagem do kernel para atender o gerenciamento, uma vez que os bootloaders podem não lidar com eles separadamente.
Informações mais precisas é fortemente recomentado consultar o site oficial do DeviceTree.
Fundamentos do Device Tree
Como diversas plataformas embarcadas possuem dspositivos de hardware que o kernel não pode identificar dinamicamente, existe duas formas de se fazer isso. Em algumas plataformas, os componentes e dispositivos são descritos através de códigos em C diretamente dentro dos fontes do kernel. Contudo alguns optam por uma abordagem mais flexível que é a utilização de uma linguagem de descrição de harware especial, o Device Tree.
O Device Tree é uma estrutura de dados que descreve o tipo e a configuração dos dispositivos de hardware. Em especial, são descritos os componentes físicos anexados ao barramento do processador.
O formato é derivado de um bootloader da Sun Microsystem chamado de OpenBoot, que foi formalizado como as especificações de padrão IEEE. Ele foi empregado em arquiteturas para Macintosh baseados em PPC e em PPC Linux também. Em seguida, foi adotado em diversas implementações de ARM Linux e outras tantas arquiteturas.
Na prática é um arquivo com extensão .dts, este arquivo é composto por uma estrutura hierárquica que descreve especificamente os componentes de hardware que compõem o sistema.
Por exemplo, é possível se descrever dispositivos de hardware externos conectados à barramentos I2C. Ou mesmo, descrever certas multiplexações de pinos do processador, ou quis sinais do SoC estarão disponíveis no conector externo.
Um exemplo básico de Device Tree pode ser visto no código abaixo.
cpus {
cpu@0 {
compatible = "arm,cortex-a9";
};
cpu@1 {
compatible = "arm,cortex-a9";
};
};
serial@101F0000 {
compatible = "arm,pl011";
};
serial@101F2000 {
compatible = "arm, pl011";
};
gpio@101F3000 {
compatible = "arm, pl061";
};
interrupt-controller@10140000 {
compatible = "arm, pl190";
};
spi@10115000 {
compatible = "arm, pl022";
};
Como mecnionado as Device Tree, estruturas de dados que descrevem os componentes de hardware, são dependêntes de cada plataforma, já que descrever suas especificações.
Assim como os arquivos de configuração do kernel Linux, é possível listar as Device Trees disponíveis nos fontes do kernel:
ls arch/arm/boot/dts
aks-cdu.dts
alphascale-asm9260-devkit.dts
alphascale-asm9260.dtsi
alpine-db.dts
alpine.dtsi
am335x-baltos.dtsi
am335x-baltos-ir2110.dts
am335x-baltos-ir3220.dts
am335x-baltos-ir5221.dts
am335x-baltos-leds.dtsi
am335x-base0033.dts
am335x-boneblack-common.dtsi
am335x-boneblack.dts
am335x-boneblack-wireless.dts
am335x-boneblue.dts
am335x-bone-common.dtsi
am335x-bone.dts
[..]
Dentre estas é possível, temos interesse na descrição da plataforma que estamos utilizando no treinamento, então filtrando as arquiteturas pelo nosso chip:
ls arch/arm/boot/dts | grep bcm2710-
bcm2710-rpi-3-b.dtb
bcm2710-rpi-3-b.dts
bcm2710-rpi-3-b-plus.dtb
bcm2710-rpi-3-b-plus.dts
bcm2710-rpi-cm3.dtb
bcm2710-rpi-cm3.dts
Assim, podemos visualizar o nosso Device Tree de interesse
cat bcm2710-rpi-3-b.dts
/dts-v1/;
#include "bcm2710.dtsi"
#include "bcm283x-rpi-smsc9514.dtsi"
/ {
compatible = "raspberrypi,3-model-b", "brcm,bcm2837";
model = "Raspberry Pi 3 Model B";
chosen {
bootargs = "8250.nr_uarts=1";
};
aliases {
serial0 = &uart1;
serial1 = &uart0;
};
};
&gpio {
spi0_pins: spi0_pins {
brcm,pins = <9 10 11>;
brcm,function = <4>; /* alt0 */
};
spi0_cs_pins: spi0_cs_pins {
brcm,pins = <8 7>;
brcm,function = <1>; /* output */
};
i2c0_pins: i2c0 {
brcm,pins = <0 1>;
brcm,function = <4>;
};
....
No caso da Raspberry 3 Model B+, devemos utilizar o seguinte Device Tree:
cat bcm2710-rpi-3-b-plus.dts
Compilando o Device Tree
Existe um compilador específico para Device Trees o dtc. Este está disponível no diretório scripts/dtc.
Para realizar a compilação das estruturas de Device Trees de todas as placas/arquiteturas habilitadas no arquivo de configuração do kernel Linux, basta executar o comando make, especificando a variável de da arquitetura e a ferramenta de cross-compilação:
make ARCH=arm CROSS_COMPILE=arm-linux- dtbs
E para compilar somente o Device Tree da sua placa, no nosso caso a RPi 3, é necessário identificar o nome do arquivo de configuração (arquivo com a extensão .dts) e executar o comando make sobre o mesmo.
make bcm2710-rpi-3-b.dtb
O arquivo compilado, .dtb, é disponibilizado dentro do diretório dos Device Trees, arch/arm/boot/dts.
Realizando o boot com o U-Boot
Como apresentado anteriormente, nas versões mais recentes do U-Boot é possível carregar a imagem zImage. Em versões antigas necessitavam do arquivo uImage.
O U-Boot também suporta passar o arquivo compilado, o Device Tree Blob (.dtb), como um parâmetro do kernel.
Conforme o procedimento já realizado, o processo básco envolve, carregar o arquivo zImage no endereco X da memória RAM e o arquivo .dtb no endereço Y da memória RAM. E Iniciar o kernel Linux com o comando:
bootz X - Y
Onde o símbolo -, india a ausência de um initramfs. Caso haja dúvidas é possível reler o material da seção U-Boot, em especial o roteiro prático do Laboratório Bootloader.
Parâmetros Command Line
Conforme apresentado na prática de Bootloader, em especial a etapa de montagem do U-Boot, é possível também passar parâmetro de inicialização do kernel Linux sem a necessidade de recompilá-lo.
Revisitando este conceito, temos que os parâmetros são passados através de uma string que define vários argumentos para o kernel Linux:
- root=: indica o caminho do RootFS;
- console=: redirecionamento do terminal para algum periférico;
- rootwait: espera indefinidademente a inicialização do dispositivo onde o RootFS esta armazenado.
Além disso, pode ser definido, ainda no U-Boot a variável bootargs. Bem como pode ser definido dentro do próprio Device Tree, quando a plataforma utilizar-se de um.
Outra maneira de ser definido é durante a configuração do kernel, através da variável CONFIG_CMDLINE. Contudo, como esperado a imagém do kernel possuirá estes argumentos internamente.
Por fim, há um caso específico da RPi 3 que é o arquivo cmdline.txt, que permite ser definido. Para mais informações basta consultar a página dos parâmetros do kernel.
Limpando as Configurações do Kernel
Normalmente é um padrão dos scripts Makefiles, remover imagens, arquivos objetos, binários, bibliotecas e outros arquivos temporário. Para tal, basta invocar o comando clean:
make clean
Além de remover todos os arquivos gerados, remove também os de configuração:
make mrproper
[LAB] Kernel Cross-Compilling
Nesta atividade, os fontes do kernel Linux serão baixados e a partir deles, será realizada a configuração para compilar uma imagem para a RPi3, a compilação da imagem, a gravação na RPi3 e a inicialização do kernel através do U-Boot.
Baixando os fontes do kernel Linux
A Raspberry Pi Foundation fornece os fontes do kernel para as placas RPi em seu repositório oficial e estes foram os fontes baixados para esta atividade. Assim como outras ferramentas, eles se encontram no diretório ∼/dsle20/dl/kernel/linux-rpi-4.14.y.zip. Crie uma pasta chamada kernel dentro de dsle2020 e em seguida, extraia os fonte do kernel nela e entre no diretório extraído:
cd ~/dsle20
mkdir kernel
cd kernel
unzip ~/dsle20/dl/kernel/linux-rpi-4.14.y.zip
cd linux-rpi-4.14.y
Configurando o kernel
Conforme apresentado em aula, o kernel possui suporte para muitas arquiteturas diferentes. É possível visualizá-las através do diretório arch:
ls arch/
alpha arm64 cris hexagon m32r microblaze nios2 powerpc sh um xtensa
arc blackfin frv ia64 m68k mips openrisc s390 sparc unicore32
arm c6x h8300 Kconfig metag mn10300 parisc score tile x86
Além disso, o kernel também possui suporte especifico para a mesma arquitetura, porém de fabricantes diferentes. Por exemplo, mach-bcm refere-se SoCs da Broadcom, mach-exynos a SoCs da Samsung, mach-sti da ST, e assim por diante:
ls arch/arm
boot mach-at91 mach-imx mach-netx mach-sa1100 mach-zynq
common mach-axxia mach-integrator mach-nomadik mach-shmobile Makefile
configs mach-bcm mach-iop13xx mach-nspire mach-socfpga mm
crypto mach-berlin mach-iop32x mach-omap1 mach-spear net
firmware mach-clps711x mach-iop33x mach-omap2 mach-sti nwfpe
include mach-cns3xxx mach-ixp4xx mach-orion5x mach-stm32 oprofile
Kconfig mach-davinci mach-keystone mach-oxnas mach-sunxi plat-iop
Kconfig.debug mach-digicolor mach-ks8695 mach-picoxcell mach-tango plat-omap
Kconfig-nommu mach-dove mach-lpc18xx mach-prima2 mach-tegra plat-orion
kernel mach-ebsa110 mach-lpc32xx mach-pxa mach-u300 plat-pxa
kvm mach-efm32 mach-mediatek mach-qcom mach-uniphier plat-samsung
lib mach-ep93xx mach-meson mach-realview mach-ux500 plat-versatile
mach-actions mach-exynos mach-mmp mach-rockchip mach-versatile probes
mach-alpine mach-footbridge mach-moxart mach-rpc mach-vexpress tools
mach-artpec mach-gemini mach-mv78xx0 mach-s3c24xx mach-vt8500 vdso
mach-asm9260 mach-highbank mach-mvebu mach-s3c64xx mach-w90x900 vfp
mach-aspeed mach-hisi mach-mxs mach-s5pv210 mach-zx xen
Como pode-se perceber, o suporte do kernel Linux às mais variadas plataformas é bem grande. Além dos exemplos acima, existem ainda muitos arquivos de configurações prévias, relacionados a diferentes placas para cada arquitetura. Observe:
ls arch/arm/configs/
acs5k_defconfig eseries_pxa_defconfig mps2_defconfig rpc_defconfig
acs5k_tiny_defconfig exynos_defconfig multi_v4t_defconfig s3c2410_defconfig
am200epdkit_defconfig ezx_defconfig multi_v5_defconfig s3c6400_defconfig
aspeed_g4_defconfig footbridge_defconfig multi_v7_defconfig s5pv210_defconfig
aspeed_g5_defconfig gemini_defconfig mv78xx0_defconfig sama5_defconfig
assabet_defconfig h3600_defconfig mvebu_v5_defconfig shannon_defconfig
at91_dt_defconfig h5000_defconfig mvebu_v7_defconfig shmobile_defconfig
axm55xx_defconfig hackkit_defconfig mxs_defconfig simpad_defconfig
badge4_defconfig hisi_defconfig neponset_defconfig socfpga_defconfig
bcm2709_defconfig imote2_defconfig netwinder_defconfig spear13xx_defconfig
bcm2835_defconfig imx_v4_v5_defconfig netx_defconfig spear3xx_defconfig
bcmrpi_defconfig imx_v6_v7_defconfig nhk8815_defconfig spear6xx_defconfig
cerfcube_defconfig integrator_defconfig nuc910_defconfig spitz_defconfig
clps711x_defconfig iop13xx_defconfig nuc950_defconfig stm32_defconfig
cm_x2xx_defconfig iop32x_defconfig nuc960_defconfig sunxi_defconfig
cm_x300_defconfig iop33x_defconfig omap1_defconfig tango4_defconfig
cns3420vb_defconfig ixp4xx_defconfig omap2plus_defconfig tct_hammer_defconfig
colibri_pxa270_defconfig jornada720_defconfig orion5x_defconfig tegra_defconfig
colibri_pxa300_defconfig keystone_defconfig palmz72_defconfig trizeps4_defconfig
collie_defconfig ks8695_defconfig pcm027_defconfig u300_defconfig
corgi_defconfig lart_defconfig pleb_defconfig u8500_defconfig
davinci_all_defconfig lpc18xx_defconfig prima2_defconfig versatile_defconfig
dove_defconfig lpc32xx_defconfig pxa168_defconfig vexpress_defconfig
dram_0x00000000.config lpd270_defconfig pxa255-idp_defconfig vf610m4_defconfig
dram_0xc0000000.config lubbock_defconfig pxa3xx_defconfig viper_defconfig
dram_0xd0000000.config magician_defconfig pxa910_defconfig vt8500_v6_v7_defconfig
ebsa110_defconfig mainstone_defconfig pxa_defconfig xcep_defconfig
efm32_defconfig mini2440_defconfig qcom_defconfig zeus_defconfig
em_x270_defconfig mmp2_defconfig raumfeld_defconfig zx_defconfig
ep93xx_defconfig moxart_defconfig realview_defconfig
Perceba que a maioria das ferramentas de desenvolvimento para Sistemas Linux Embarcado seguem um padrão de configuração no intuito de facilitar o processo para o desenvolvedor.
O processo para carregar um arquivo de configuração prévia do kernel, é o mesmo como no crosstool-ng e U-Boot. No entanto, por padrão o kernel considera a mesma arquitetura da maquina de desenvolvimento e, portanto, é necessário configurar a arquitetura para ARM. O arquivo de configuração da RPi3 é o bcm2709_defconfig:
export ARCH=arm
make bcm2709_defconfig
A partir deste momento, as configurações básicas para compilar um kernel funcional para a RPi 3 foram carregadas e salvas em um arquivo chamado .config no diretório raiz dos fontes do kernel. Antes de compilar, acesse o menuconfig e verifique a quantidade de funcionalidades, drivers, protocolos de comunicação que o kernel oferece suporte:
make menuconfig
Antes de compilar o kernel é necessário definir também o toolchain, pois por padrão o processo de build do kernel irá utilizar as ferramentas nativas. Assim, defina a variável CROSS_COMPILE e compile o kernel:
export CROSS_COMPILE=arm-linux-
make -j4
Ao final do processo de compilação, as imagens geradas se encontrarão no diretório boot da arquitetura utilizada:
ls -l arch/arm/boot
Compilando o Device Tree
A RPi 3 faz uso de Device Tree para disponibilizar as informações de hardware ao kernel. Os fontes de Device Tree fornecidos encontram-se na pasta arch//boot/dts:
ls arch/arm/boot/dts
A lista é bem longa. Os fontes para a RPi 3 e RPi 3 Plus são **bcm2710-rpi-3-b.dts e bcm2710-rpi-3-b- plus.dts respectivamente. Compile de acordo com sua placa:
make bcm2710-rpi-3-b.dtb
ou
make bcm2710-rpi-3-b-plus.dtb
Após a compilação, o objeto final especificado em um dos comandos acima, estará disponível na pasta arch/arm/boot/dts.
Gravando as novas imagens e bootando a RPi3
Agora é com você. Com as explicações dadas em aula em conjunto com as atividades anteriores, você deverá ser capaz de realizar esta etapa. Copie os arquivos recém-compilados para a RPi via scp:
- Faça um backup do script do U-Boot (
boot.src) com o comandocp; - Faça também um backup do Device Tree fornecido pelo Raspian (
bcm2710-rpi-3-b.dtb); - Todos esses arquivos encontram-se na partição
/boot/do seu cartão SD; - Após realizar os backups, gere um novo
boot.scrcom a ferramentamkimagedo U-Boot alterando a imagem do kernel parazImage; - Copie os seguintes arquivos na sua partição
/boot:zImage,bcm2710-rpi-3-b.dtbeboot.scr. - Para testar se o prodimento funcionou podemos obter a versão do kernel através do comando
uname -rou mesmodmesg | grep Linux. Invoque os comandos antes e depois de da prática.